- 総合TOP
- 宇宙
- AI
- ロボット
- WEB3・メタバース
スマートフォンの顔認証や画像検索、異常検知など、私たちの身近なAI技術の裏側で活躍しているのが「オートエンコーダー」です。この技術は、データを圧縮して本質的な特徴だけを取り出す、AIの重要な基盤技術となっています。しかし、その仕組みについて理解している人は多くありません。本記事では、オートエンコーダーの基本的な仕組みを分かりやすく解説します。
オートエンコーダーとは?
オートエンコーダーとは、入力データを一度圧縮(エンコード)してから、元に戻す(デコード)ことを学習するニューラルネットワークです。わざわざ圧縮して戻す意味があるのか不思議に思うかもしれませんが、この過程で「データの本質的な特徴」を抽出できるのです。
海外旅行で荷物を詰めるときのことを想像してみてください。限られたスーツケースに必要なものだけを厳選して詰め(エンコード)、目的地で再び取り出して使う(デコード)ような感覚です。この過程で「本当に必要なもの」が何かを学んでいくのです。
二つの顔を持つAI:エンコーダーとデコーダー
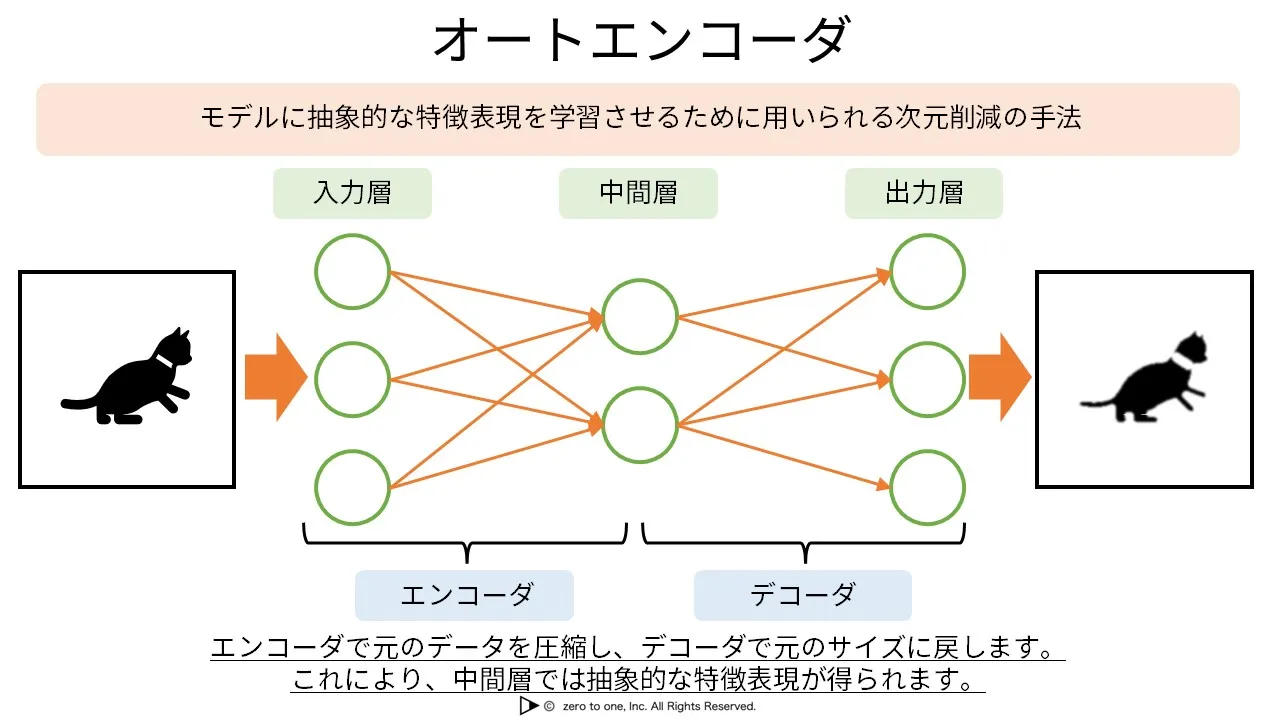
(引用元:zero to one)
オートエンコーダーは主に二つの部分から構成されています。これらが連携することで、データの圧縮と復元という一連の処理を実現しています。
エンコーダー:情報を圧縮する役割
エンコーダーは、入力データを受け取り、それを小さな「潜在表現」に圧縮します。これは、大量の情報から「エッセンス」だけを抽出する作業です。
例えば、顔写真を考えてみましょう。目、鼻、口といった特徴の位置関係や、肌の色調、表情などの情報を、少ないデータ量で表現します。「この人は丸顔で、大きな目を持ち、笑顔が特徴的」といった情報だけを残すイメージです。
デコーダー:圧縮した情報を復元する役割
デコーダーは、圧縮された「潜在表現」を受け取り、できるだけ元のデータに近い形に復元します。完全に同じにはならないものの、重要な特徴は保持されています。
この「完全には戻らない」という性質が、実は重要なポイントです。オートエンコーダーは、復元の際にノイズや細かい変動を除去するため、データの本質的な部分だけを学習することになります。
オートエンコーダーの種類と進化
オートエンコーダーには、基本形に加えてさまざまな応用バージョンが存在します。例えば、ノイズ除去オートエンコーダーは、わざと入力にノイズを加えてから学習させることで、より頑健なモデルを作り出します。変分オートエンコーダー(VAE)は、確率的な要素を取り入れて、新しいデータを生成する能力を持ちます。
これらの発展形は、画像生成AIなど、より複雑なAI技術の基盤にもなっています。単なる「圧縮と復元」を超えて、創造的な能力を持つAIへと進化しているのです。
日常生活の中のオートエンコーダー活用例
オートエンコーダーは、さまざまな分野で活用されています。
●画像処理:ノイズ除去や画像の鮮明化。監視カメラの映像から不要な背景を除去したり、古い写真を修復したりする技術に応用されています。
●異常検知:工場の機械の異常や、クレジットカードの不正利用を検出。「通常と違う」パターンを見つけ出すことが得意です。
●推薦システム:ECサイトや動画配信サービスの「おすすめ」機能。ユーザーの好みの本質的な特徴を捉えて、新しい商品を提案します。
●医療画像分析:MRIやCTスキャンのようなメディカルイメージから重要な特徴を抽出し、診断支援に役立てられています。医師の目には見えにくい微細な変化を検出することもあります。
データの「本質」を捉えるAIの目
オートエンコーダーは、一見単純な「圧縮して戻す」という仕組みの中に、データの本質を見抜く深い知恵が隠れています。人間が無意識のうちに行っている「重要な情報を選び取る」という作業をAIに教えた技術と言えるでしょう。
今後、データ量が爆発的に増加する社会において、オートエンコーダーのような「本質を見抜く技術」はますます重要になってくるはずです。AIの基礎技術を知ることで、私たちの周りのテクノロジーをより深く理解する一助になれば幸いです。



- share
-

-

-