- WEB3・メタバース
- ロボット
AIに学習させる方法は様々あり、そのひとつがニューラルネットワーク(Neural Network)。人間の脳の動きを真似してデータをAIに処理させる機械学習のモデルです。
人間の脳内にある「ニューロン(神経細胞)」と、その「繋がり方」をヒントに作られています。何気なく使っている機械やシステム、ロボット、様々な部分に用いられている機械学習のモデルです。今回はその基礎を解説していきましょう。
脳をヒントにした「学習する仕組み」
人間がりんごを見て、りんごだと認識できるのは、脳内の神経細胞ネットワークが情報を処理しているからです。ニューラルネットワークは、この「情報を受け取り、処理して、次に渡す」という脳の基本動作をコンピューター上で再現しています。
従来のコンピュータープログラムがすべて人間の設計したルールに従って動作するのに対し、ニューラルネットワークはデータを基に自ら「学習」することができます。これがAI技術の革命的な特徴であり、人間が明示的にルールを書かなくても、データから自動的にパターンを見つけ出せるのです。
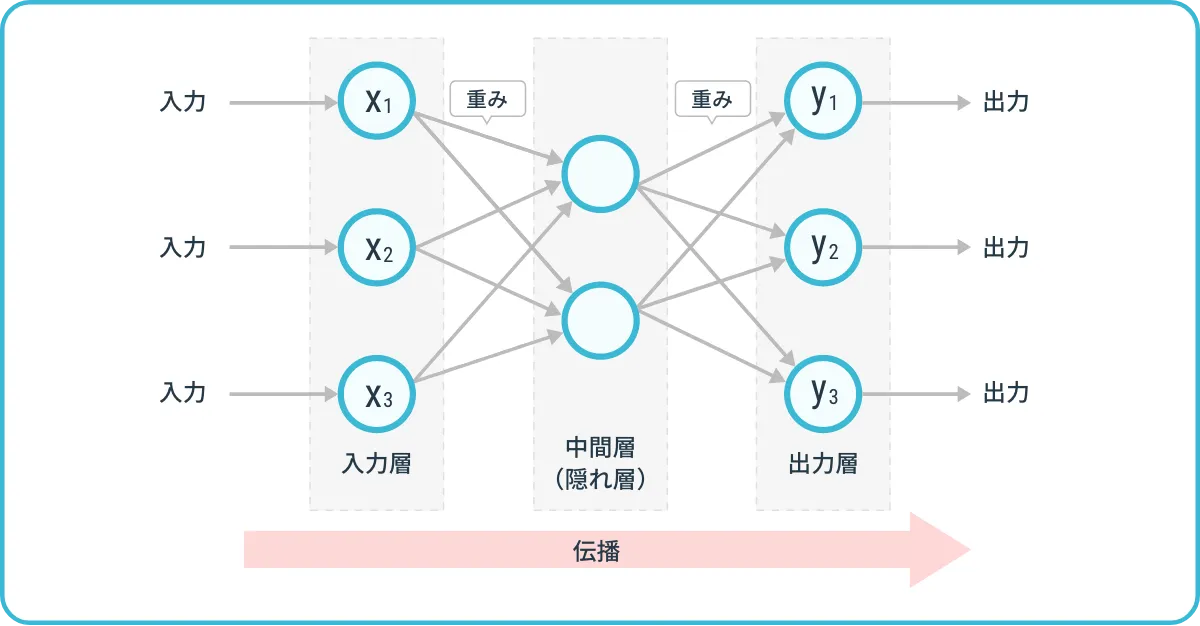
3つの層と「重み」の関係
ニューラルネットワークは、以下の3種類の層で構成されています。
●出力層:処理結果を出力する最後の層
各層には「ニューロン」と呼ばれる計算ユニットがあり、層と層の間で互いに接続されています。この接続には「重み」という数値が設定されています。
「重み」は、友達関係の親密度に例えられます。ある友達からの提案は、あなたの判断に大きく影響するかもしれませんが、別の友達からの同じ提案はあまり影響しないかもしれません。ニューラルネットワークでも同様に、ある入力からの情報が出力にどれだけ影響するかは「重み」によって決まります 。
(引用元:AIsmiley)
また、各ニューロンには「バイアス」という値も設定されており、これは判断の傾向や閾値を調整する役割を果たします。日常生活で例えると、あなたが元々甘いものが好きな場合、甘いデザートの提案には肯定的に反応しやすいようなものです。
「学習」の本質:間違いから学ぶ
ニューラルネットワークの最大の特徴は「学習する」能力です。学習の中心となるのは「バックプロパゲーション(誤差逆伝播法)」という方法で、これは「間違いを発見して修正する」人間の学習法と似ています。
●繰り返し:これを何度も繰り返して精度を向上させる
料理の味付けに例えると、塩を入れる→「塩が多すぎる」と指摘される→次は塩を少なめにする→練習を繰り返して、ちょうどいい塩加減を覚える、というプロセスに似ています。
具体例:文字認識の仕組み
手書き数字の認識を例に考えると、
●出力層:「これは8である確率が95%」といった判断を出力
もし「8」を「3」と誤認識したら、システムは重みを調整し、次回は正しく認識できるように学習します。このプロセスを大量のデータで繰り返すことで、精度が向上していきます。
ニューラルネットワークの進化:単純なものから複雑なものへ
ニューラルネットワークは時代とともに進化してきました。最初は単純な「パーセプトロン」と呼ばれる構造(入力層と出力層のみ)から始まり、隠れ層を持つ「多層パーセプトロン」、そして現在注目されている「深層学習(ディープラーニング)」へと発展してきました。
深層学習では、隠れ層が何層も重なった深い構造を持ち、より複雑なパターンや特徴を学習できます。例えば画像認識では、最初の層が線やエッジを、中間層が目や鼻などの特徴を、深い層が顔全体などを認識するというように、層ごとに異なるレベルの特徴を学習します。
まとめ:ニューラルネットワークの本質
ニューラルネットワークの本質は「経験から学び、パターンを見つけ出す能力」にあります。従来のプログラミングが「If A then B(もしAならBせよ)」というルールで動くのに対し、ニューラルネットワークは「このデータはどんなパターンを持っているのか?」を自分で発見します。
この特性により、文字認識や画像分類、自然言語処理など、従来のプログラミングでは困難だった複雑なパターン認識タスクで、優れた性能を発揮できるのです。ただし、「なぜそのような判断をしたのか」という説明が難しい「ブラックボックス問題」など、課題も残されています。



- share
-

-

-

